
Subscribe for cutting-edge B2B tech research.
See Value Better
Spear is a fundamental asset manager focused on industrial technology. We help you do more than passively track the broader market.

Diving Deep into the AI Value Chain
Over the past year the world has woken up to the vast potential of AI. The unparalleled pace of AI discoveries, hardware improvements, and model introductions is putting data and AI strategy at the forefront of investors’ and organizations’ priorities. We believe that AI will usher in the next generation of product and software innovation, and we’re already seeing the early signs of this reflected in company fundamentals.
In this report, we examine the different layers of AI. While most people are focused on the application layer, there is a lot more to the AI opportunity. We go over the three layers (1) hardware (2) data infrastructure (3) applications.
We believe that the hardware opportunity is significantly larger and broader than what’s incorporated into expectations; we see the most underappreciated value in the data layer, and we believe the key to differentiation in the application layer will be access to proprietary data.
The Evolution of Artificial Intelligence
AI is not a new concept. What is generating all the craze is that AI is going from being able to only perform programmed, predictive tasks to it being able to put things in context and generate conclusions.
The first wave of AI was learned perception and inference, like recognizing images, understanding speech, and recommending a video or an item to buy. The early Natural Language Processing (NLP) models trained in 2018 were only able to perform visual search/image recognition and contained less than 100 million parameters.
What changed was that the hardware to train these models got significantly more powerful, and a new model, known as the Transformer Model, provided a unique framework for making use of these hardware capabilities. The Transformer Model is the foundational model behind Chat GPT/GPT3 and most other Large Language Models (LLMs) trained today. It is a neural network that learns context, making it a breakthrough in AI.
The current wave of innovation is focused on Natural Language Processing (NLP), which gives the ability to understand text and spoken words in a similar way that humans do. ChatGPT, introduced in late 2022, is revolutionizing online search and was the first AI application available at a mass scale (or accessible to everyone). But there are many other relatively easy applications of NLP such as smart assistants, chatbots, e-mail filtering, document/sentiment analysis, etc.
Based on the same concept, there is a lot of innovation in coding where AI can assist in writing code (e.g. GitHub), cybersecurity where AI can assist in going through vast amount of data and identify threats and weak links, etc. Most of the applications to date have been a version of productivity improvement.
The next wave of AI, we believe, will be AI interacting with the physical world. Examples are digital twins, autonomous driving, robots, avatars, etc. We are still very early in this third wave. Even areas, such as autonomous driving that many believe are close to reality are closer to the start line than the finish line. This is because the innovation done to date is not based on generative AI but predictive, where many technological developments hit bottlenecks. Many predictive models plateaued in the pace of performance improvements despite the massive growth in data.

The Three Different Layers of the AI Opportunity
While most investors have been focused on the application layer (ChatGPT, Copilot 365, GitHub Copilot), there is a lot more to the AI opportunity.
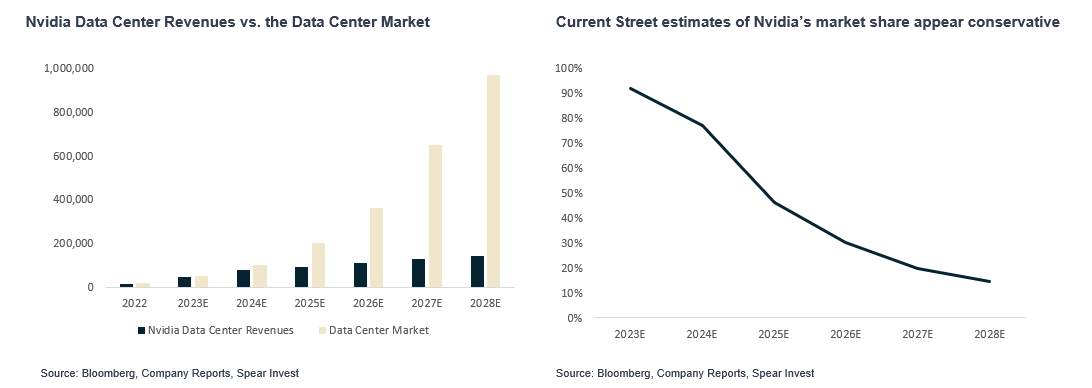
The Hardware Layer was the first to see sizable fundamental improvement in earnings in 2Q23 with Nvidia Data Center growing from close $300 million in 2018 to ~$40-50bn annualized run rate today. With such outsized growth, investors are wondering if demand was pulled forward. We expect ~$1trillion compute opportunity in the next 4-5 years. We also believe that the opportunity is broader than just compute and there are many relatively smaller markets such as memory, networking, energy management (e.g., liquid cooling) that will see exponential growth. The hardware opportunity is relatively known by investors and therefore we do not expect outsized moves (100%+ upside) going forward. We do believe that there is still attractive opportunities as there is potential for upward estimate revisions, which would imply compounding upside.
The Data Infrastructure Layer is where we expect to see outsized opportunities in 2024. Over the past year, we went through a spend optimization cycle. Companies noted budget cuts by their customers, increased deal scrutiny, etc. While some level of optimizations is a norm and we expect to continue, the cloud service providers (such as AWS and Azure) and companies across data ecosystem (such as Snowflake and Datadog) noted a meaningful pick up in demand in 4Q23 with new AI workloads offsetting optimizations. While the initial impact has been only in single digit % of revenue, we believe that AI is a data problem and we are just in the early innings of data companies seeing an inflection.
The Application Layer is expected to be the largest TAM (total addressable market), but it is also the most crowded and competitive space. It is comprised of startups and incumbent players. The incumbents have large installed bases and access proprietary data, which provides them with a significant advantage.
Let’s dig into each layer.
The Hardware Layer
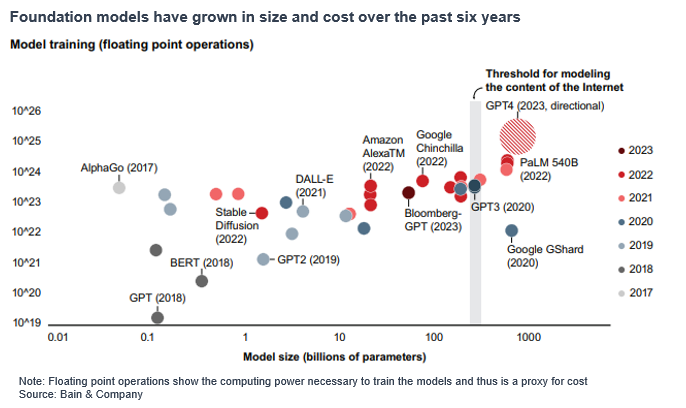
From a hardware perspective, Model sizes grew from < 100 million parameters to >500 billion over the span of 5 years. The predictive wave was built on hardware with tens to several hundred million parameters.
- ELMo trained in 2018 was able to perform a visual search – image recognition and contained 26M parameters
- BERT-Large trained in 2019 was able to flag sentiment and provide basic Q&A – contained 340M parameters
- The current LLMs contain>500bn parameters.

Consistent with this is growth in model sizes, Nvidia’s Data Center revenues realized a big step up. Data Center revenue had already grown at a healthy 40% CAGR, but 2023 marked an inflection.
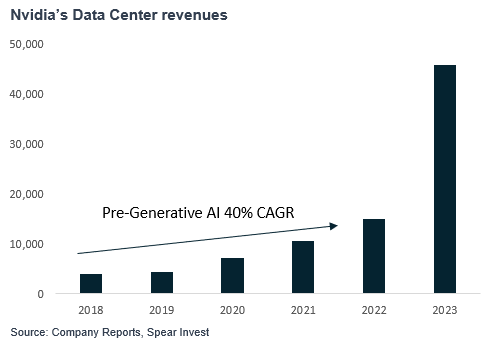
CPUs have been the dominant data center processor over the past cycle. They are a serial processor, which means that they process one instruction at a time. As the compute requirements for generative AI increased exponentially, the need for parallel processing emerged (performing multiple calculations simultaneously). This is what made GPUs, a parallel processor originally used for computer graphics, the core processor for AI. It is important to understand the size and scale of these chips.
Nvidia’s H100 is comprised of 35,000 parts and nearly 1 trillion transistors in combination. It weighs 70 pounds. It takes a robot to build and takes a supercomputer to test a supercomputer. – Jensen Huang, CEO of Nvidia
The market for GPUs has grown exponentially is expected to be a ~$1trillion market in 4-5 years. Compute (GPUs and CPUs) is where most of the Data Center upgrade budgets are going but it is not all. In order to optimize the performance of the data center, the performance of the system is very important. As GPU performance has significantly improved, the bottlenecks are in bandwidth, memory, etc. These tangential markets, although not as large as the compute layer, are meaningful in size and can offer similar upside in terms of growth.
For example, Networking last year was a $2bn market expected to grow to $10bn in 5 years. Nvidia just pointed out on their most recent earnings call that networking now exceeds a $10 billion annualized revenue run rate. Strong growth was driven by exceptional demand for InfiniBand, which grew fivefold year-on-year. InfiniBand is critical to gaining the scale and performance needed for training LLMs.

Similarly, Liquid Cooling was a $2bn market last year expected to grow in the teens. We expect to see significantly higher growth rates. Cooling represents 40% of data center’s energy consumptions, and although GPUs require 2x less energy to perform a similar task to a CPU, the exponential growth in GPUs is coming with a significant
The current generative AI wave has been very compute intense. The compute requirements have increased exponentially with model sizes.
The current generative AI wave has been significantly more compute intense. The compute requirements have increased exponentially with model sizes. The current infrastructure (even data centers that were built 2-3 years ago) would need to be upgraded to accommodate AI workflows. The number of models that companies are developing (covered in the next section) has also surged.
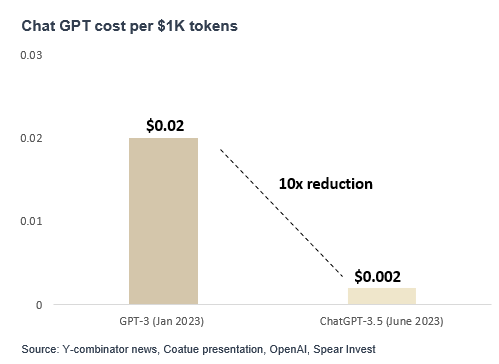
However, the cost to run models has significantly decreased
Despite companies pricing in new products at 2-3x premium to prior versions (e.g., H100 vs. A100), given that these new products offer significantly better performance, the cost to perform tasks is significantly lower.
We expect over time costs will decline further making it significantly more affordable to run models which we expect will spur even more application development.
In conclusion, accelerated computing is a very broad opportunity.
- While significant value is in the GPUs, Data Centers are systems and it is all about optimizing this system. Memory, bandwidth, and energy consumption are key pressure points.
- A big misconception is that GPUs are replacing CPUs. While it is true that GPUs are a gaining a larger slice of the pie, there is innovation necessary across the board (including in software that optimizes the use of GPUs vs. CPUs)
- Second, while LLM training and other applications that require large computing power will be done at the data center, accelerated computing usage will broaden to the edge and devices. Ultimately, every device will have some form of accelerated computing.
- Over time while the cost of running models will significantly decrease, despite the strong growth of the size of the pie.
The Data Infrastructure Layer
The generative AI and data infrastructure companies play a pivotal role in enabling the development, deployment, and operation of AI systems and LLMs. The Infrastructure stack has undergone a significant transformation over the past few decades, especially in the realms of data storage and processing.
In the early 2000s-2010s, most enterprises focused heavily on hardware databases and Relational Database Management Systems (RDBMS), which were the backbone of data storage and management. These systems resided on physical servers only supporting structured data handling and limited in scalability and flexibility. Subsequently, the advent of message queuing technologies marked a shift towards more distributed computing, facilitating asynchronous data processing and communication between applications, a precursor to today’s cloud-native capabilities.

Presently, the cloud-native paradigm ushers in a new modern AI stack powered by the major cloud providers. They provide the core cloud storage and computing services, which allows for scalable, flexible, and often more cost-effective data management solutions. They are the picks and shovels that enable the enablement of AI systems prior systems.
Cloud Service Providers
In the realm of generative AI and LLMs, cloud service providers are indispensable for their computational resources and scalability. These providers offer the essential infrastructure and platforms necessary for training and deploying sophisticated AI models.

The cloud service providers (CSPs) are the core of the AI value chain because they offer the necessary infrastructure, computing power, and storage capabilities. AI models, particularly the more advanced ones like deep learning models, require significant computational resources that are often not feasible for individual companies to maintain. Cloud service providers offer scalable, on-demand resources that allow businesses to train and deploy AI models without the overhead of building their own infrastructure. This democratizes access to AI, enabling small and large businesses alike to innovate and leverage AI technologies.
Large companies above the AI value chain such as Snowflake and Databricks will require massive compute capabilities, primarily served by Azure and AWS. Similar to how Nvidia is a secular beneficiary of who “wins” in AI, the hyperscalers that underpin the compute needs for data platforms stand to gain regardless of who emerges victorious in the AI battle. In addition to the traditional compute and storage capabilities, the CSPs have been building an additional layer on top of their infrastructure that provides companies access to pre-trained models and other tools that enable AI development (both internally developed and third party).
- Microsoft Azure (OpenAI): Microsoft with its partnership with OpenAI ushered in this new enterprise-use for LLMs. Meanwhile Microsoft doesn’t own its own core foundational model, it has chosen to build a strong partnership with OpenAI and built a large ownership stake. For Microsoft, this partnership enhances its Windows 365, Teams and Azure offerings. Microsoft has the opportunity to leverage its optimized AI cloud infrastructure, distribution, data, across their offerings to capture more share of overall enterprise IT infrastructure market. Microsoft is taking a more integrated platform approach to bundling AI into its existing SaaS and platform services, focusing on efficiently monetizing the new technology and providing customers with good value on cloud services through bundling.
- Google Cloud Platform (GCP) – DeepMind: GCP has always been known for its advanced AI capabilities, especially since acquiring DeepMind. However, in the current race to dominate the generative AI landscape, they have lagged significantly behind Microsoft. GCP is expected to have a better position in capturing the consumer market compared to Microsoft. The company has embraced heterogeneous computing, utilizing its proprietary TPU AI chip in its fourth generation, which offers a more favorable price/performance ratio than previous versions. They are also investing in their proprietary LLMs (PaLM 2, Codey, Imagen & Chirp), in conjunction with the Vertex managed cloud platform. GCP’s key strategy is to leverage its consumer appeal and incorporate some of its LLMs into their productivity apps.
- Amazon Web Services (AWS) – Bedrock: AWS has been catching up to the earlier players discussed above. They have focused on leveraging partnerships with leading Gen AI companies. They introduced Bedrock, a fully managed service that offers a choice of high-performing foundation models (FMs) from AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon through a single API. Bedrock simplifies the process of building, training, and deploying ML models at scale. At their recent ReInvent event, they launched Amazon Q, a new generative AI assistant for work. They also announced updates for their AWS-Designed chips – AWS Graviton4 and AWS Trainium2, which will improve the speed, cost, and energy efficiency of running generative AI and other workloads. AWS prioritizes becoming the central hosting platform for LLMs and continues to enhance Bedrock while maintaining strong partnerships with leading startups. In the future, we expect AWS to develop its own proprietary models, AI chips, and training/inference accelerators.
Foundational Models
Foundational Model (FM) companies develop large-scale models that are the underlying components that power LLMs and generative AI. These AI models can be adapted for various applications and are the backbone of numerous AI applications, from natural language processing to creative content generation. Foundational models are trained on vast datasets and require significant resources, both in terms of data and computational power. These are pre-trained models that lower the barrier to entry for AI application development, to enable more organizations build AI-driven solutions.
There are two broad categories of foundational models;
- Closed-source proprietary models
- Open-source foundational models.
Closed-source proprietary models are models where their source code is not publicly available, but they can be accessed using APIs. Closed-source models often come with more advanced technical sophistication – more robust support, regular updates, and are tailored for specific commercial applications. Leading FM companies like OpenAI have models with higher performance and have off-the-shelf services that make it easier for developers to get up and running. Meanwhile, open-source models such as Stability’s Stable diffusion and Meta’s Llarma2 are built on open-source software which allows for community driven changes to source code.

There will be use cases for both open and closed source models. We believe that large companies with the ability to hire AI engineers, will lean towards open-source FMs meanwhile many SMBs will lean toward utilizing the existing closed-source models. Large enterprises will likely use both, if will likely lean toward open models because it provides them with greater customization and flexibility. Users can modify and tailor open-cloud models to their specific needs, offering greater flexibility in application development.
Data Platforms
The role of database companies in the AI value chain is to manage and facilitate the effective use of data, which is the lifeblood of AI. AI models are only as good as the data they are trained on. Database companies provide the tools and platforms to store, manage, and process large volumes of data efficiently. They are responsible for ensuring data quality, consistency, and accessibility, which are critical for training accurate and reliable AI models.

In Databricks’ latest report on the use cases for machine learning, they highlighted that natural language processing (NLP) dominated other types of use-cases by users. NLP is a rapidly growing field that enables businesses to gain value from unstructured textual data like large documents or summarizing content or extracting sentiment from customer reviews. These NLP use cases dominated 49% of Python libraries used.

Databricks reported experiencing a significant rise in the number of transformer -related libraries usage on their platform relative to SaaS LLM APIs and adjacent tools. These transformer-related software libraries and frameworks were specifically designed to support the implementation of Transformer models within an enterprise. These libraries provide pre-built modules, and functions that simplify the process of building, training, and deploying Transformer-based models. Examples include TensorFlow and PyTorch, which offer extensive support for Transformer architectures, enabling developers to create sophisticated LLMs with relative ease.
SaaS LLM APIs and LLM tools are more easily allow developers to integrate advanced language processing features into their applications without needing to build and train their models. These APIs, offered by companies like OpenAI, Google, and others, provide access to pre-trained models via cloud-based platforms. Users can tap into these powerful models for a variety of applications such as text generation, translation, summarization, and more, typically on a subscription or pay-per-use basis.
LLM Tools, meanwhile, refer to the broader set of tools and platforms that facilitate the use, management, and optimization of LLMs. This includes user interfaces for interacting with LLMs, tools for fine-tuning models on specific datasets, and systems for monitoring and evaluating model performance. These tools are designed to make it easier for a wider range of users – not just AI specialists – to benefit from the advances in language understanding and generation offered by LLMs.
This data by suggests that enterprises are preferring to implement solutions that allow them to customize, train and deploy their own transformer model rather than utilize an already existing API from OpenAI. We believe this is an important shift that should serve as a tailwind for companies like Databricks and Snowflake.
Data Lakehouse vs. Data Cloud
Databricks
Databricks is a cloud-based platform designed for large-scale data processing and analytics. They provide an integrated environment for data engineering, data science, and analytics, built atop a powerful and optimized version of Apache Spark, which is a leading open-source data processing framework. The Databricks Lakehouse is central to Databricks’ approach, blending the capabilities of data lakes and data warehouses to support various data types and structures, allowing for efficient data storage at scale. The unified Lakehouse concept brings together one platform for integration, storage, processing, governance, sharing, analytics, and AI.
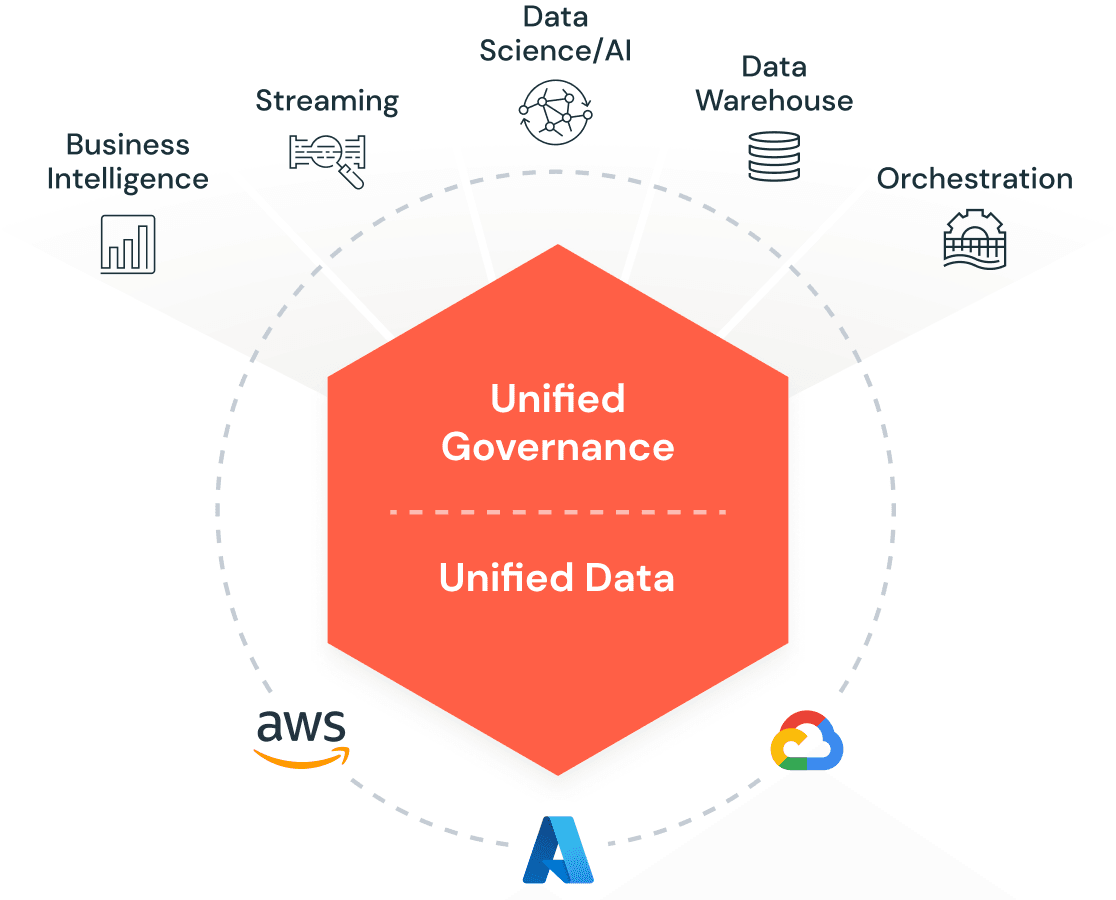
Source: Databricks “Lakehouse” Platform
While already considered a key player in the AI stack, Databricks has emboldened its position as a leader in GenAI through investments in models like Dolly (an open-source instruction-following LLM) and their big-ticket acquisition of MosaicML. This acquisition further bolstered Databrick’s AI presence within the enterprise as this product enables companies efficiently build their large generative AI models on their own data and business processes. Databricks continues to echo the message that their Lakehouse is the best way for gen-native startups to train and deploy their own AI models, leveraging their proprietary data in a cost-effective manner without being tied to Big Tech.
Overall, Databricks is well positioned to support startups who want to build their own generative AI models without having being tied to Big Tech. Their development of Dolly and the acquisition of Mosaic ML further helps them capitalize on a future where more and more companies want to be able to build out their transformer models.
Snowflake:
Snowflake is a cloud-based data platform designed to facilitate data storage, processing, and analytics, with a strong focus on scalability and ease of use. At its core, Snowflake separates storage and compute functionalities, allowing users to scale each independently in the cloud. This architecture is particularly beneficial for handling large datasets and complex queries, making it a popular choice among data professionals, including AI and ML engineers.
Snowflake started out as a data warehousing solution, which allowed for centralized storage and management of data, supporting both structured and semi-structured data types. However, in recent years, they have expanded their platform to incorporate more data lake features that enable user to store unstructured data in its native format, or unstructured data where are particularly useful for AI/ML use-cases.
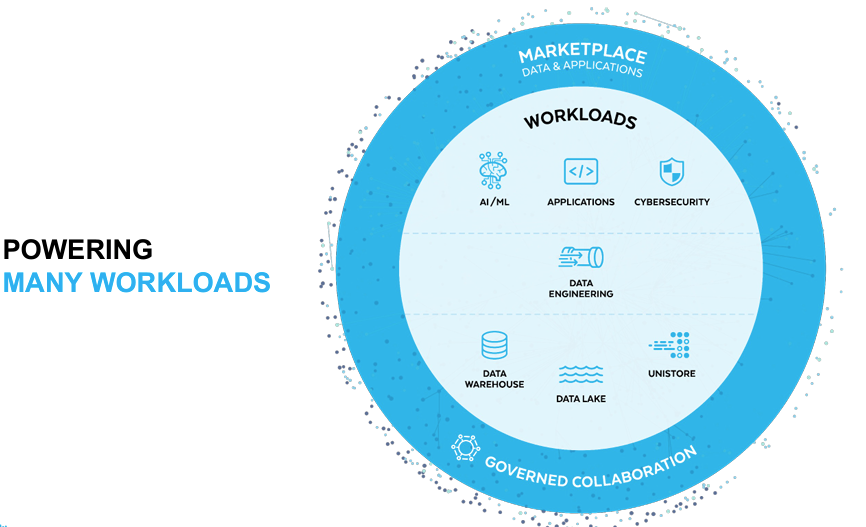
Source: Snowflake Investor Presentation
Snowflake announced several notable partnerships with NVIDIA, Microsoft, and Weights & Biases. The partnership between allows Snowflake to incorporate Nvidia’s NeMo enterprise developer framework into its Data Cloud, which will allow Snowflake customers to build and deploy LLMs and AI-driven applications leveraging proprietary data that resides in Snowflake. They have also built out partnerships with companies like Weights & Biases, Alteryx, Hex, Dataiku, RelationalAI, Pinecone, and more.
Snowflake vs. Databricks
With the proliferation of Generative AI applications, both companies are trying to position themselves as strategic multiproduct data platforms. Below, we highlight a few of the major announcements from the respective conferences and our thoughts on each company’s overall AI strategy.
Databases
Transactional Databases:
MongoDB – Companies like MongoDB provides a document-based database model and schemaless architecture, which plays a key role in Generative AI. Furthermore, discovery and exploration of new use-cases and application-building serves as a demand-driver for MongoDB’s consumption-based model. Additionally, MongoDB is expanding platform features with vector search, for example. Vector databases have received investor interest as a better-suited offering for AI/ML capabilities.
Vector Databases:
Generative AI and LLMs deal with massive amounts of data, often in unstructured forms like text, images, and audio. Vector databases are designed to efficiently handle, index, and retrieve these large datasets. They convert complex data into vector representations, making it easier to manage and process at scale. One of the primary functions of vector databases is facilitating advanced search capabilities. They allow for more nuanced and context-aware searches, which is essential in applications powered by generative AI and LLMs, such as personalized content recommendations, image recognition, and natural language processing tasks. Companies such as Pinecone, Weviate are leading players within this market.
In the world of generative AI, the ability to process and analyze data in real-time is crucial. Vector databases support this need by providing the infrastructure to quickly retrieve and analyze data vectors, enabling real-time responses and interactions in AI applications. As generative AI technologies and LLMs continue to grow, the demand for scalable database solutions that can handle increased loads without compromising performance becomes essential. Vector databases are inherently scalable, making them well-suited for these evolving needs. They play a significant role in MLOps, particularly in the deployment, monitoring, and maintenance of AI models. They facilitate the operational aspects of managing large-scale AI models by providing efficient ways to store and access the data these models need.
These category refers to MLOps and AIOps companies who bridge the gap between AI model development and operational deployment. They address the complexities involved in managing the lifecycle of AI and ML models, around generative AI and LLMs. This management includes the automation of model deployment, monitoring model performance, ensuring scalability, and managing the infrastructure needed for these AI models to function optimally.
Developer Tooling

Companies within this category are primarily focused helping to operationalize generative AI models. They include: Data labelling and curation companies, companies that support model hub and fine tuning, model inferencing, LLM Ops and monitoring and evaluation.
- Data streaming, transformations and pipeline companies such as Confluent, play a key role in role of data streaming and processing in the AI value chain. Data must be pre-processed before it hits the LLM. This includes extracting relevant context from data stores across the organization, transforming the data into a usable format, and loading the data into the model’s context window. In the context of generative AI and LLMs, the real-time data processing capabilities of Confluent enable the continuous and efficient flow of data, which is a prerequisite for training and updating LLMs. Generative AI models, especially those used in language processing, sentiment analysis, and content creation, rely heavily on vast, diverse, and often real-time data. Confluent’s platform facilitates the collection and processing of this data from various sources, ensuring that it is readily available for AI models. This is crucial for keeping the models updated and relevant, a key factor in their effectiveness and accuracy.
- Data Labelling companies such as ****Scale.AI and Snorkej play a critical role in labelling of data for training AI models, including LLMs. These companies specialize in annotating and categorizing data to make it usable for training AI models. The accuracy and quality of data labelling directly impact the effectiveness of AI models. In generative AI, where models are often trained on vast datasets, the role of these companies becomes even more critical. They ensure that the data fed into LLMs is well-structured and accurately labelled, leading to more effective and reliable models.
- Fine-Tuning companies such as Hugging Face, Databricks (with MosaicML) play a crucial role in adapting pre-trained LLMs to specific tasks or industries. Companies specializing in fine-tuning help customize these models to suit particular use cases, enhancing their relevance and performance. This process involves adjusting model parameters based on additional, often domain-specific data or specialized market needs.
- Monitoring and Evaluation companies such as Weight & Biases, Arthur and Gantry are crucial for maintaining the accuracy, fairness, and reliability of AI models. Companies in this space provide tools and services for ongoing assessment of model performance, monitoring for biases, drifts, and other issues that can arise over time. This is essential not only for model accuracy but also for ethical considerations, ensuring that generative AI models are used responsibly.
- LLM Ops companies such as Langchain and Weight & Biases specialize in the operational aspects of LLMs, providing tools and services tailored to the unique challenges and requirements of these models. Langchain focuses on leveraging LLMs for language-centric applications. Their contribution lies in making it easier for organizations to integrate LLMs into their systems and workflows. Langchain provides tools and frameworks that help businesses harness the power of LLMs for various applications, such as chatbots, content generation, and natural language understanding tasks. They simplify the process of embedding LLMs into existing applications, making it more accessible for companies to adopt these advanced technologies.
Cybersecurity and Observability
As AI becomes more prevalent, the importance of cybersecurity escalates. AI systems process and generate vast amounts of data, some of which are sensitive or proprietary. Cybersecurity ensures the integrity, confidentiality, and availability of this data. Moreover, as AI systems increasingly make decisions that affect the real world, ensuring these systems are secure from tampering or malicious use is paramount. Cybersecurity firms play a crucial role in safeguarding AI systems from external threats and ensuring that AI is used responsibly and ethically.

Proper data governance and LLM security will be critical to enterprise deployment. Domain specialists like Credal (data loss prevention), Calypso (content governance), and HiddenLayer (threat detection and response) allow companies to securely connect internal data stores to third-party foundation models or customer-facing AI applications—ensuring full transparency, auditability, and traceability.
The advances in Generative AI have significantly changed the security landscape. Both attackers and defenders are rapidly adopting the technology and the results are material in changing the mechanics of responses. Attackers have the edge as they are able to adopt and deploy their techniques much faster than the defenders. Many of the emerging companies are still developing to respond to these new types of attacks. There are two key ways of thinking about the impact of AI cybersecurity.
- AI for security
- Security for AI
AI for security:
Over the past decade, AI has already been embedded in security. Some them include security systems for protecting data from unauthorized access and ensuring adherence to regulatory requirements. The industry is facing a vast shortage in talent and the current talent can’t keep up the rise of attacks.
Security for AI:
ChatGPT lowers the barrier to entry for threat actors and opens the door to more malware, phishing, and identity-based ransomware attacks. Cybercriminals have already found ways around ChatGPT’s content filters and policies, which are meant to prevent malware-based code generation. Phishing attacks are another key attack vector in focus, as ChatGPT can quickly produce authentic-looking and highly personalized emails to target an end-user’s identity credentials. One of the effects of the rise of these types of attacks is that we’re going to need more technologies around email security, identity security, and threat detection.
Human-written defensive software may not be enough to combat AI-generated malware which has drastic implications for cybersecurity. The weakest link in the cybersecurity chain, regardless of how much companies spend, are the human users. Cybercriminal have learned about how to use malicious code written by ChatGPT to exploit victims. As discussed, there are risks around social phishing attacks as a risk, where AI chatbots reliably extract sensitive company or personal information via impersonation and there are risks of disinformation whereby false AI-generated messages are used in the public.
Case Studies:
SentinelOne and Crowdstrike
Crowdstrike and SentinelOne are case studies of companies implementing AI across their product lines. Both companies have incorporated AI into their products over the past decade. As core endpoint protection platforms, they combine vast amounts of data collected on the endpoint with information from adjacent platforms like cloud, identity, and devices.
These platforms have created large data lakes that capture data and respond to threats across the attack surface. They use AI-based telemetry to detect and respond to threats in real-time. CrowdStrike’s threat graph stores over 40 petabytes of data, handles trillions of events per day, and services 70 million requests per second. This makes their AI algorithm powerful and able to provide an unprecedented level of security with significant automation. Over the past few months, Crowdstrike launched Charlotte AI in August. Similarly, SentinelOne launched its PurpleAI, a generative AI chatbot dedicated to threat-hunting, analysis, and response.
Zscaler highlighted on their recent earnings call, Zscaler Risk 360. This is the industry’s first holistic AI-powered risk quantification and mitigation solution. It delivers up-to-date risk posture and recommends corrective actions to mitigate risk in a timely fashion. Zscaler has already closed 10 plus Risk360 deals and are in active evaluations with over 100 enterprises. For those deals, Zscaler already generates over 6-figure ACV on average, and they expect it to grow over time. Risk360 provides critical insights to CISOs when reporting on cybersecurity risk, strategy and governance, particularly in light of new SEC regulations.
There are also many use cases of Palo Alto Networks deploying their AI models in their security co-pilots for network security, XSIAM in security operations, and AI in cloud security. Cloudflare has demonstrated use cases around edge AI inferencing on edge devices. We envision many more use-cases around AI being incorporated within the company’s platform.
Observability
Observability in the context of AI refers to the ability to monitor and understand the internal states of AI systems. As AI models become more complex and autonomous, understanding their decision-making process becomes challenging. Observability tools help in diagnosing problems, understanding model performance, and ensuring transparency. This is crucial not only for maintaining operational efficiency but also for building trust in AI systems. It involves monitoring model performance, data drift, and other operational metrics to ensure that AI systems function as intended. For generative AI and LLMs, which are inherently complex and data-intensive, observability becomes even more critical.
As more companies are driven to adopt AI into their enterprise stack, they have to move more workloads to the cloud to enable those functions. Companies like Datadog, Grafana, and New Relic provide comprehensive monitoring and analytics tools that are essential for the deployment and maintenance of AI models. These tools offer insights into the performance of AI systems, tracking metrics such as response times, error rates, and resource utilization. Such monitoring is vital to ensure that the AI models are functioning as intended and delivering the expected outcomes. On Datadog’s recent earnings call, they cited examples where they are providing AI observability functionalities for some of the leading model providers. While Datadog isn’t a direct beneficiary, we see them as a secondary effect beneficiary of the rise of more AI applications.
Application Layer
Over the past 10 years, companies have been undergoing digital transformation with the rise of the cloud. Rapid software development has been at the heart of this emergence of the cloud. Now, with the emergence of LLMs, we are at the cusp of an exponential rise in the number of applications developed. AI applications have the potential to supercharge this transformation. Nvidia’s CEO, Jensen Huang, famously said earlier this year:
There are five million applications in app stores, there are probably several hundred PC applications, and there are 350,000, maybe 500,000 websites that matter — how many applications are there going to be on large language models? I think it will be hundreds of millions, and the reason for that is because we’re going to write our own! – Jensen Huang, March 2023, An Interview with Nvidia’s CEO on Strategy.
We have gone from a world with hundreds of apps during the PC and Internet days to a world with millions of apps in the mobile era. It is not a massive stretch to believe that we are now entering a world where apps built on LLMs can be customized to the needs and wants of individual users.

The most widely talked about AI application that people are familiar with is ChatGPT, but we believe enterprises will be the biggest TAM for AI applications. By types of products, this layer can be divided into several sub-groups:
Horizontal AI:
Horizontal applications, in the context of generative AI and LLMs (Language Model Models), refer to versatile solutions that address common needs or functions applicable to multiple sectors. These applications are characterized by their wide-ranging applicability and can significantly improve workflow efficiency. As AI advances in reasoning, collaboration, communication, learning, and prediction capabilities, next-generation workflow tools will not only automate routine tasks but also take on work that was previously only possible for humans, using advanced approaches like agents and multi-step reasoning.
Examples of such tools include Jasper and Copy.ai, which are content generation tools capable of creating marketing copy, writing code, or generating reports, regardless of the industry. The advantage of horizontal applications lies in their vast market potential, as they cater to a wide range of users and industries. However, their broad applicability often means they are less specialized and may require further customization or adaptation to meet specific industry needs.
Vertical AI:
Vertical applications, on the other hand, are specialized solutions tailored to the specific needs and challenges of a particular industry or sector. These applications are deeply integrated into the workflows, processes, and regulatory frameworks of their target industry, offering more customized solutions.
Companies can utilize AI to develop industry-specific applications, transforming human-machine collaboration and enabling end-to-end automation rather than just serving as a copilot or collaboration platform. We are witnessing examples of this in various sectors. In healthcare, AI-driven applications are revolutionizing diagnostics and patient care. In finance, they are being used for fraud detection and personalized financial planning. The potential impact of AI is vast and diverse, with significant implications. For instance, at the most recent AWS Re-Invent event, Pfizer noted that they expect to achieve annual cost savings of $750 million to $1 billion from some of their priority AI use cases. Pfizer is already leveraging the power of AI across 17 use cases, including scientific and medical content generation, manufacturing, and prototypes using Amazon Bedrock.
Within enterprises, the opportunity set can be divided into two broad areas by use case:
- Enhancing growth
- Reducing costs

Reducing costs
This is the area with the most AI use cases today. There have been several innovative productivity improvement tools that have already proven to be delivering significant benefits. The first and largest use case based on NLP models was coding assistants. Two large scale examples:
- Microsoft’s GitHub. On its most recent conference call Microsoft noted that the company’s coding assistant Github has now over 1 million paid Copilot users and more than 37,000 organizations that subscribe to Copilot for business (+40% qoq) The number of developers using GitHub has increased 4x since our acquisition 5 years ago and is estimated to be increasing developer productivity by up to 55%, according to Microsoft.
- Similarly GitLab has released products like GitLab AI Code suggestions (Beta) that provide either the entire code snippet or a complete line of active code when building applications. In the future, there will be cases where AI will help developers automate more mundane tasks and enhance Security. These are samples of where we see AI enhancing the productivity of developers and driving additional growth for software companies.
According to a Bain AI survey this year, nearly 60% of software engineers expect AI to improve productivity by more than 20%.

In addition to coding assist, the applications for AI powered assistants are significantly broader (e.g., Microsoft 365 Copilot, chatbots, customer service assistants).
Growing revenues
The revenue enhancement side has two main components (1) increasing sales and marketing effectiveness (2) developing products. We are still in the early innings.

Application category need to fix the retention:
A piece from Sequoia explored application that have experienced record sign-ups compared to retention. ChatGPT set the record for the first application ever to reach 100 million users. However, its retention rate has been much lower compared to other peers that reached that milestone earlier.
Users crave AI that makes their jobs easier and their work products better, which is why they have flocked to applications in record-setting droves. User engagement is also lackluster. Some of the best consumer companies have 60-65% DAU/MAU; WhatsApp’s is 85%. By contrast, generative AI apps have a median of 14% (with the notable exception of Character and the “AI companionship” category).
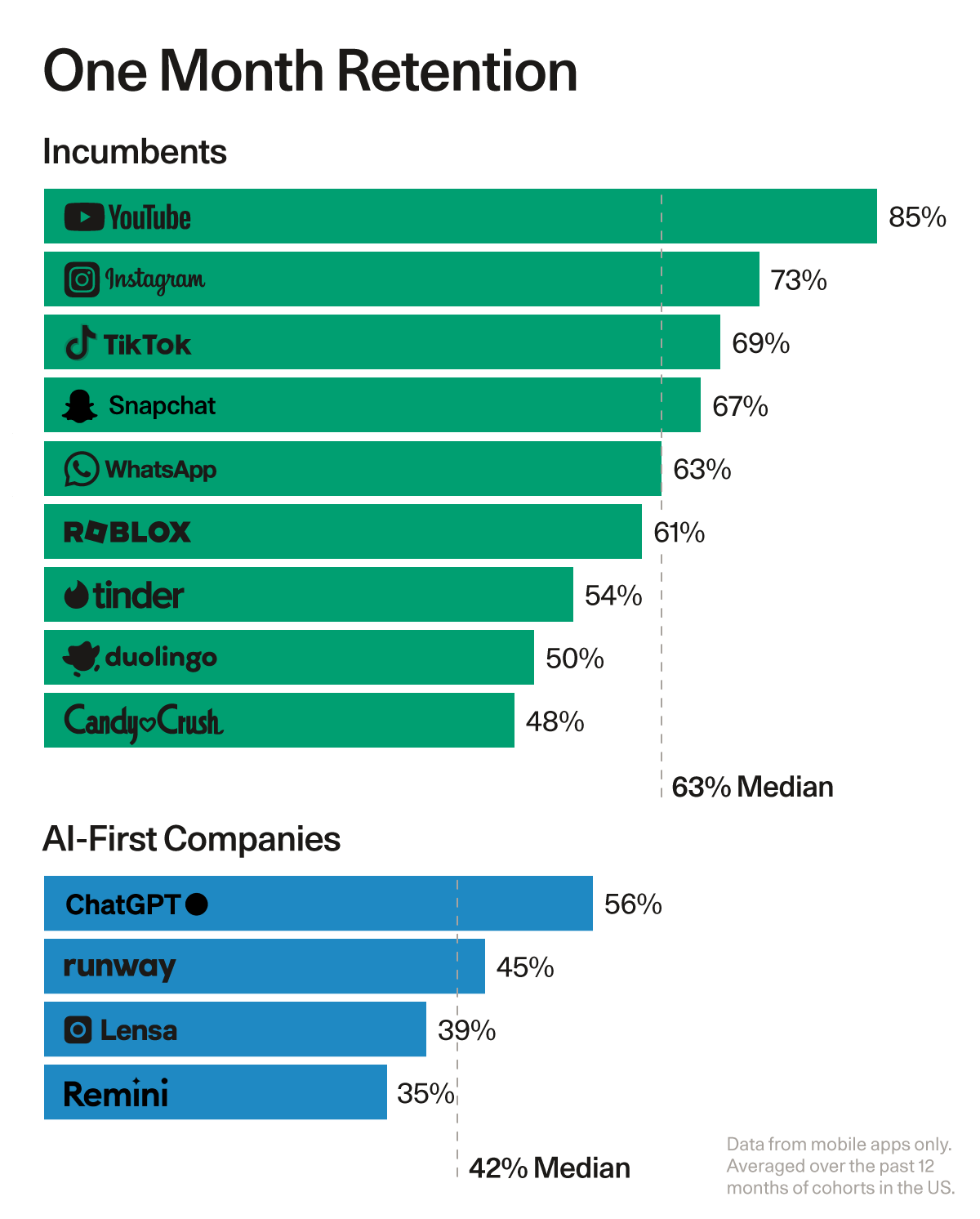
Source: Sequoia Generative AI’s Act Two
This means that users are not finding enough value in Generative AI products to use them every day yet. generative AI’s biggest problem is not finding use cases or demand or distribution, it is proving value. It is also important to consider what aspect of the enterprise or consumer ecosystem would generate the highest retention overtime. Right now, we know that Horizontal applications promise broad market reach and versatility, making them attractive for widespread adoption and rapid growth. Vertical applications, by contrast, offer tailored solutions with deep industry integration, appealing to sector-specific needs and often commanding higher value
Who will capture the value?
Although we expect that most of the value will be captured by the customers (i.e., enterprises using these AI tools), AI can still provide a meaningful uplift for product pricing.
There are two criteria that we have identified as key especially when it comes to capturing value at scale:
- Possessing large installed bases that can be upsold
- Access to proprietary data
1. Large Installed Base
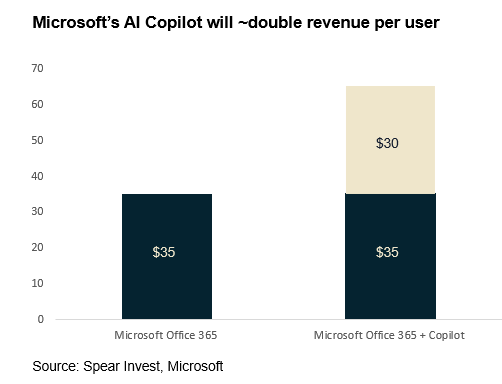
In the first category, large installed bases, companies can charge a small fraction of the ultimate benefit and still generate meaningful revenue uplift. A good example is Microsoft, where we expect that the newly introduced co-pilot can add $5-16bn of incremental revenue, assuming only a 5-16% adoption. The $30/month price tag would close to double the revenue for the customers that adopts this solution. Background read on the Office 365 Copilot announcement here: Axios.2. Proprietary data is crucial – but more is not always betterIn the first category, large installed bases, companies can charge a small fraction of the ultimate benefit and still generate meaningful revenue uplift. A good example is Microsoft, where we expect that the newly introduced co-pilot can add $5-16bn of incremental revenue, assuming only a 5-16% adoption. The $30/month price tag would close to double the revenue for the customers that adopts this solution. Background read on the Office 365 Copilot announcement here: Axios.
In this category of large installed bases would be CRM systems providers (Salesforce, Hubspot), E-commerce platforms (Shopify, Amazon), Design software
- More than 195K companies use Hubspot at scale
- 150K customers use Salesforce
- 1.75 million merchants sell on Shopify
- Over 200 million people use Autodesk
2. Proprietary data is crucial – but more is not always better
The second criteria is access to proprietary data. This category again puts the incumbent players at a significant advantage.
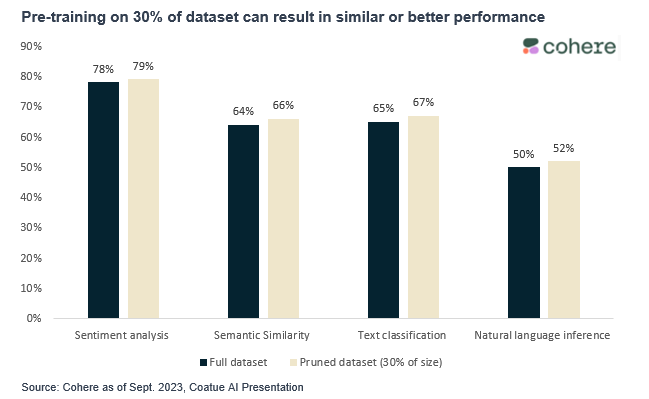
The most important thing to highlight is that the quality of the data is even more important than the quantity. According to Cohere, a leading LLM provider, training models on a fraction of the data set can result in similar to better performance.
While there are thousands of AI applications, we believe that a significant portion of the value will be captured by incumbent players. There is still room for innovation and start-ups, but a tighter interest rate environment and limited capital availability make it tougher for small companies to succeed. We believe that strategic acquisition rather than IPOs will be the more common path in the business evolution.
Large incumbents will also benefit from a favorable M&A environment where a proven platform approach will be particularly valuable. We have already seen several interesting deals in cybersecurity (Palo Alto/Talon, Crowdstrike), and data infrastructure (Snowflake/Neeva, Databricks/MosaicML).
Conclusion:
We are still in the early innings of the next technology wave amplified by AI. We have only scratched the surface of the ultimate opportunity by starting to upgrade the hardware infrastructure that enables AI model training and development.
We expect that the hardware cycle will be much more broad and durable than investors expect. We are finding the most underappreciated opportunities in the data infrastructure layer, which is evolving at a rapid pace. In the application layer, we believe that incumbents that have access to proprietary data and large installed bases will capture a significant portion of the value.
**
[addtoany]